In a contemporary information architecture, combined analytics allow you to access the information you require, whether it’s saved in an information lake or an information storage facility. In specific, we have actually observed an increasing variety of clients who integrate and incorporate their information into an Amazon Redshift information storage facility to examine substantial information at scale and run complicated questions to attain their company objectives.
Among the most typical usage cases for information preparation on Amazon Redshift is to consume and change information from various information shops into an Amazon Redshift information storage facility. This is typically accomplished by means of AWS Glue, which is a serverless, scalable information combination service that makes it much easier to find, prepare, move, and incorporate information from numerous sources. AWS Glue offers an extensible architecture that allows users with various information processing usage cases, and works well with Amazon Redshift. At AWS re: Create 2022, we revealed assistance for the brand-new Amazon Redshift combination with Apache Glow readily available in AWS Glue 4.0, which offers improved ETL (extract, change, and load) and ELT abilities with enhanced efficiency.
Today, we are happy to reveal a brand-new and improved visual task authoring abilities for Amazon Redshift ETL and ELT workflows on the AWS Glue Studio visual editor. The brand-new authoring experience provides you the capability to:
- Begin quicker with Amazon Redshift by straight searching Amazon Redshift schemas and tables from the AWS Glue Studio visual user interface
- Versatile authoring through native Amazon Redshift SQL assistance as a source or custom-made preactions and postactions
- Simplify typical information filling operations into Amazon Redshift through brand-new assistance for INSERT, TRUNCATE, DROP, and combine commands
With these improvements, you can utilize existing changes and adapters in AWS Glue Studio to rapidly produce information pipelines for Amazon Redshift. No-code users can finish end-to-end jobs utilizing just the visual user interface, SQL users can recycle their existing Amazon Redshift SQL within AWS Glue, and all users can tune their reasoning with custom-made actions on the visual editor.
In this post, we check out the brand-new structured interface and dive deeper into how to utilize these abilities. To show these brand-new abilities, we display the following:
- Passing a custom-made SQL sign up with declaration to Amazon Redshift
- Utilizing the outcomes to use an AWS Glue Studio visual change
- Carrying Out an APPEND on the outcomes to fill them into a location table
Establish resources with AWS CloudFormation
To show the AWS Glue Studio visual editor experience with Amazon Redshift, we supply an AWS CloudFormation design template for you to establish standard resources rapidly. The design template produces the list below resources for you:
- An Amazon VPC, subnets, path tables, a web entrance, and NAT entrances
- An Amazon Redshift cluster
- An AWS Identity and Gain Access To Management (IAM) function connected with the Amazon Redshift cluster
- An IAM function for running the AWS Glue task
- An Amazon Simple Storage Service (Amazon S3) container to be utilized as a short-term place for Amazon Redshift ETL
- An AWS Tricks Supervisor trick that keeps the user name and password for the Amazon Redshift cluster
Keep In Mind that at the time of composing this post, Amazon Redshift MERGE remains in sneak peek, and the cluster produced is a sneak peek cluster.
To release the CloudFormation stack, finish the following actions:
- On the AWS CloudFormation console, pick Produce stack and after that pick With brand-new resources (requirement)

- For Design template source, choose Upload a design template file, and submit the offered design template
- Select Next
- Go into a name for the CloudFormation stack, then pick Next

- Acknowledge that this stack may produce IAM resources for you, then pick Submit

- After the CloudFormation stack is effectively produced, follow the actions discussed at https://docs.aws.amazon.com/redshift/latest/gsg/rs-gsg-create-sample-db.html to fill sample tickit information into the produced Redshift Cluster
Checking out Amazon Redshift checks out
In this area, we discuss the brand-new read performance in the AWS Glue Studio visual editor and show how we can run a custom-made SQL declaration by means of the brand-new UI.
- On the AWS Glue console, pick ETL tasks in the navigation pane.

- Select the Visual with a blank canvas, since we’re authoring a task from scratch, then pick Produce

- In the blank canvas, pick the plus indication to include an Amazon Redshift node of type Source

When you close the node selector, and you need to see an Amazon Redshift source node on the canvas in addition to the information source residential or commercial properties.
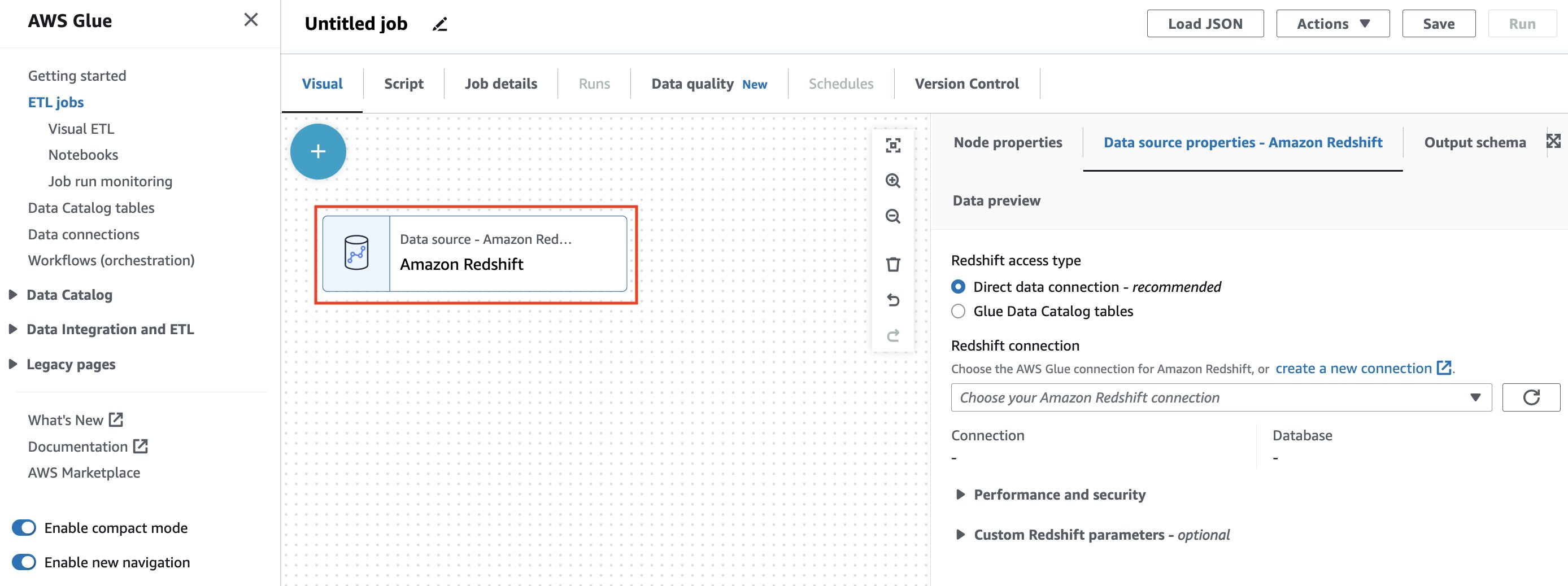
You can select from 2 techniques of accessing your Amazon Redshift information:
- Direct information connection — This brand-new approach enables you to develop a connection to your Amazon Redshift sources without the requirement to brochure them
- Glue Information Brochure tables — This approach needs you to have actually currently crawled or produced your Amazon Redshift tables in the AWS Glue Information Brochure
For this post, we utilize the Direct information connection alternative.
- For Redshift gain access to type, pick the Direct information connection
- For Redshift connection, pick your AWS Glue Connection
redshift-demo-blog-connectionproduced in the CloudFormation stack.
Defining the connection instantly sets up all the network associated information in addition to the name of the database you want to link to.
The UI then provides an option on how you want to access the information from within your chosen Amazon Redshift cluster’s database:
- Select a single table– This alternative lets you pick a single schema, and a single table from your database. You can check out all of your readily available schemas and tables right from the AWS Glue Studio visual editor itself, that makes selecting your source table a lot easier.

- Go into a custom-made question — If you’re seeking to perform your ETL on a subset of information from your Amazon Redshift tables, you can author an Amazon Redshift question from the AWS Glue Studio UI. This question will be passed to the linked Amazon Redshift cluster, and the returned question outcome will be readily available in downstream changes on AWS Glue Studio.
For the functions of this post, we compose our own custom-made question that signs up with information from the preloaded occasion table and place table.
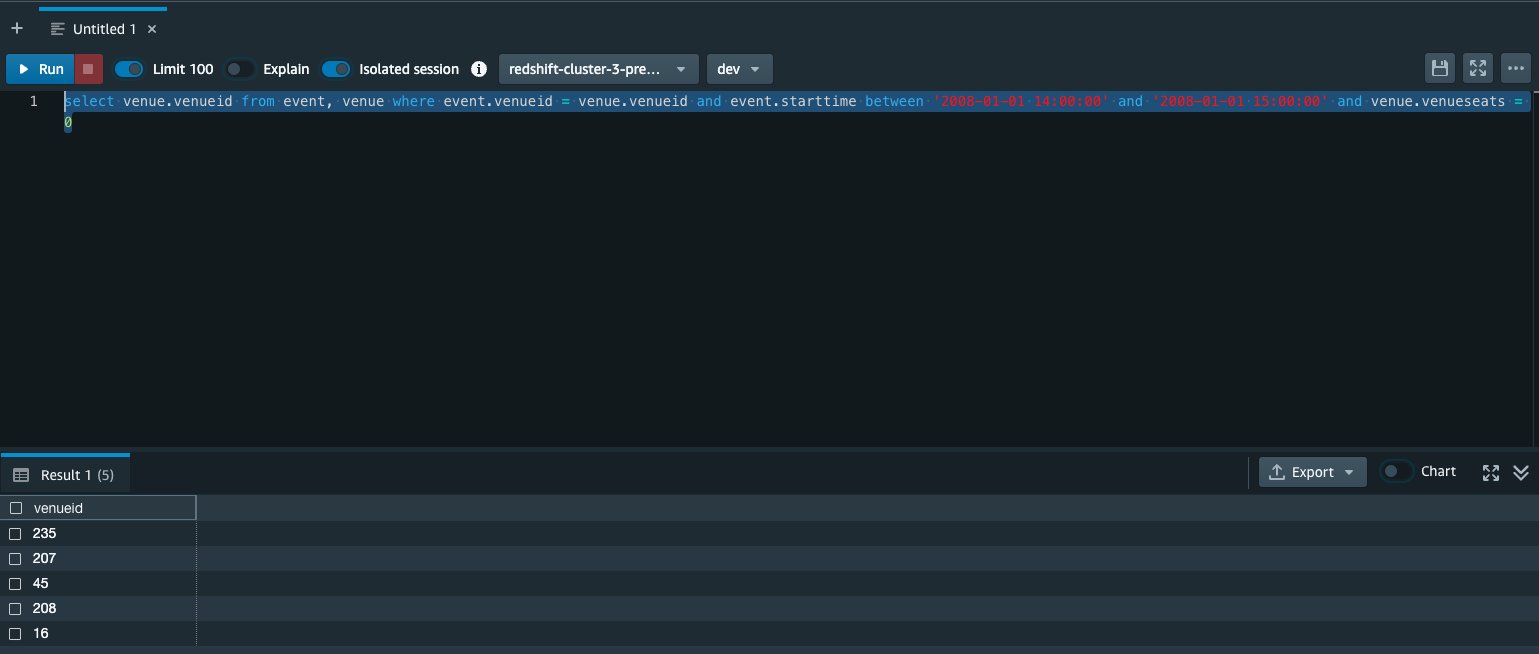
- Select Go into a custom-made question and get in the following question into the question editor:
The intent of this question is to collect the venueid of places that have actually had an occasion in between 2008-01-01 14:00:00 and 2008-01-01 15:00:00 and have actually had venueseats = 0 If we run a comparable question from the Amazon Redshift Question Editor, we can see that there are really 5 such locations within that time frame. We want to combine this information back into Amazon Redshift without consisting of these rows.
- Select Presume schema, which enables the AWS Glue Studio visual editor to comprehend the schema from the returned columns from your question.

You can see the schema on the Output schema tab.
- Under Efficiency and security, for S3 staging directory site, pick the S3 short-term directory site place produced by the CloudFormation stack ( RedshiftS3TempPath ).
- For IAM function, pick the IAM function defined by RedshiftIamRoleARN in the CloudFormation stack.

Now we’re going to include a change to drop replicate rows from our sign up with outcome. This will make sure that the MERGE operation in the following actions will not have contrasting secrets when carrying out the operation.
- Select the Drop Duplicates node to see the node residential or commercial properties.

- On the Transform tab, for Drop replicates, choose Match particular secrets
- For Keys to match rows, pick
venueid
In this area, we specified the actions to check out the output of a custom-made sign up with question. We then dropped the replicate records from the returned worth. In the next area, we check out the compose course on the exact same task.
Checking out Amazon Redshift composes
Now we discuss the improvements for composing to Amazon Redshift as a location. This area reviews all the streamlined alternatives for composing to Amazon Redshift, however highlights the brand-new Amazon Redshift MERGE abilities for the functions of this post.
The combine operator uses fantastic versatility for conditionally combining rows from a source into a location table. Combine is effective since it streamlines operations that typically were just attainable by utilizing numerous insert, upgrade, or erase declarations individually. Within AWS Glue Studio, especially with the custom-made combine alternative, you can specify a more complicated coordinating condition to deal with discovering the records to upgrade.
- From the canvas page of the task utilized in the previous area, choose Amazon Redshift to include an Amazon Redshift node of type Target

When you close the selector, you need to see your Amazon Redshift target node included on the Amazon Glue Studio canvas, in addition to possible alternatives.
- For Redshift gain access to type, choose Direct information connection
Comparable to the Amazon Redshift source node, the Direct information connection approach enables you to compose straight to your Amazon Redshift tables without requiring to have them cataloged within the AWS Glue Information Brochure.
- For Redshift connection, pick your AWS Glue connection
redshift-demo-blog-connectionproduced in the CloudFormation stack.
- For Schema, pick public

- For Table, pick the place table as the location Amazon Redshift table where we will save the merged information.
- Select combine information into target table
This choice offers the user with 2 alternatives:
- Select secrets and basic actions — This is an easy to use variation of the MERGE operation. You merely define the matching secrets, and pick what takes place to the rows that match the secret (upgrade them or erase them) or do not have any matches (insert them).
- Go into custom-made combine declaration— This alternative offers the most versatility. You can enter your own custom-made reasoning for MERGE.
For this post, we utilize the basic actions approach for carrying out a MERGE operation.
- For Handling of information and target table, choose combine information into target table, and after that choose Select secrets and basic actions.
- For Matching Keys, choose
venueid
This field will become our MERGE condition for inspecting secrets
- For When matched, pick the Erase record in the table
- For When not matched, choose Insert source information as a brand-new row into the table

With these choices, we have actually set up the AWS Glue task to run a MERGE declaration on Amazon Redshift while placing our information. Additionally, for performing this MERGE operation, we utilize the as the secret (you can pick numerous secrets). If there is an essential match with the location table’s record, we erase that record. Otherwise, we place the record into the location table.
- Browse to the Task information tab.
- For Call, get in a name for the task.
- For the IAM Function fall, pick the RedshiftIamRole function that was produced by means of the CloudFormation design template.
- Select Conserve.

- Select Run and wait on the task to complete.
You can track its development on the Runs tab.
- After the run reaches an effective state, browse back to the Amazon Redshift Question Editor.
- Run the exact same question once again to find that those rows have actually been erased in accordance to our MERGE requirements.

In this area, we set up an Amazon Redshift target node to compose a MERGE declaration to conditionally upgrade records in our location Amazon Redshift table. We then conserved and ran the AWS Glue task, and saw the impact of the MERGE declaration on our location Amazon Redshift table.
Other readily available compose alternatives
In addition to combine, the AWS Glue Studio visual editor’s Amazon Redshift location node likewise supports a variety of other typical operations:
- APPEND— Adding to your target table carries out an insert into the chosen table without upgrading any of the existing records (if there are duplicates, both records will be kept). In cases where you wish to upgrade existing rows in addition to including brand-new rows (frequently described an UPSERT operation), you can pick the Likewise upgrade existing records in target table alternative. Keep in mind that both APPEND just and UPSERT (ADD with UPDATE) are an easier subset of the MERGE performance gone over previously.
- TRUNCATE — The TRUNCATE alternative clears all the information in the existing table however maintains all the existing table schema, followed by an APPEND of all brand-new information to the empty table. This alternative is frequently utilized when the complete dataset requires to be revitalized and downstream services or tools depend upon the table schema corresponding. For instance, every night an Amazon Redshift table requires to be totally upgraded with the most recent client details that will be taken in by an Amazon QuickSight control panel. In this case, the ETL designer would pick TRUNCATE to make sure the information is totally revitalized however the table schema is ensured not to alter.
- DROP — This alternative is utilized when the complete dataset requires to be revitalized and the downstream services or tools that depend upon the schema or systems can deal with possible schema modifications without breaking.
How compose operations are being managed on the backend
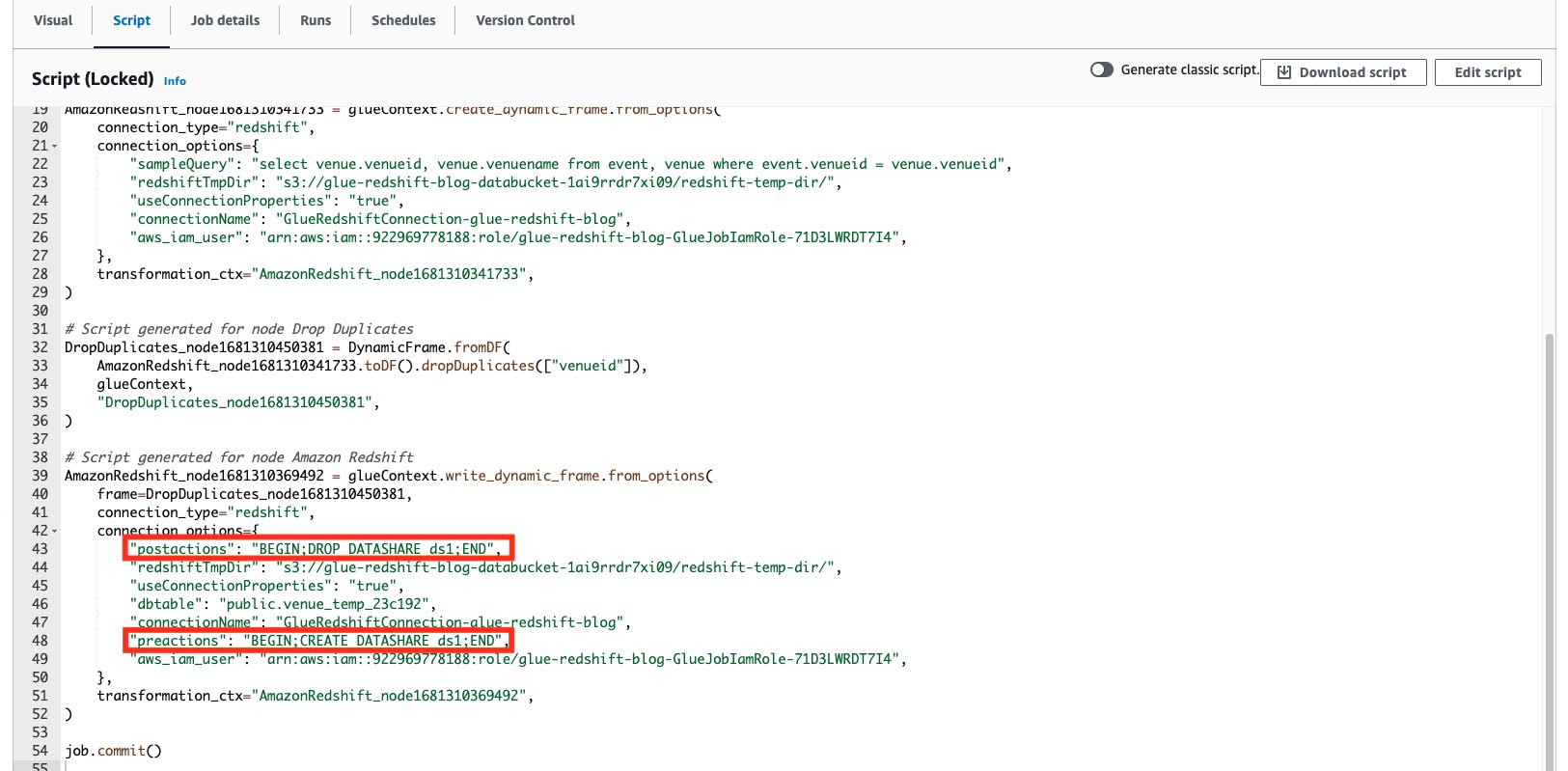
The Amazon Redshift adapter supports 2 specifications called preactions and postactions These specifications permit you to run SQL declarations that will be handed down to the Amazon Redshift information storage facility prior to and after the real compose operation is performed by Glow.
On the Script tab on the AWS Glue Studio page, we can see what SQL declarations are being run.
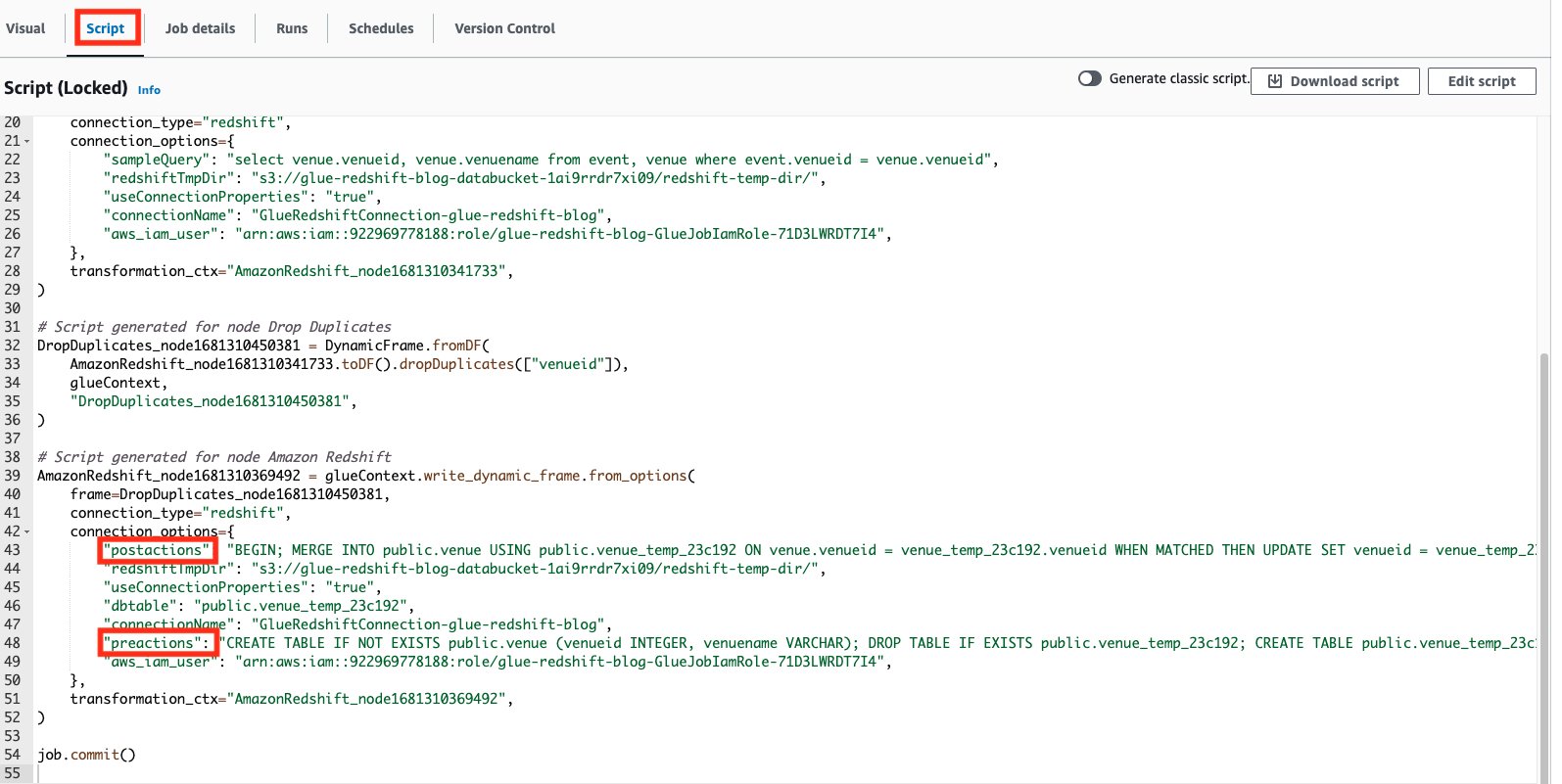
Utilize a custom-made application for composing information into Amazon Redshift
In case the offered presets need more personalization, or your usage case needs advanced applications for composing to Amazon Redshift, AWS Glue Studio likewise enables you to easily pick which preactions and postactions can be run when composing to Amazon Redshift.
To reveal an example, we produce an Amazon Redshift datashare as a preaction, then carry out the cleansing up of the exact same datashare as a postaction by means of AWS Glue Studio.
KEEP IN MIND: This area is not performed as part of the above blog site and is offered as an example.
- Select the Amazon Redshift information target node.
- On the Information target residential or commercial properties tab, broaden the Custom-made Redshift specifications area.
- For the specifications, include the following:
- Specification:
preactionswith WorthBEGIN; PRODUCE DATASHARE ds1; END - Specification:
postactionswith WorthBEGIN; DROP DATASHARE ds1; END
- Specification:
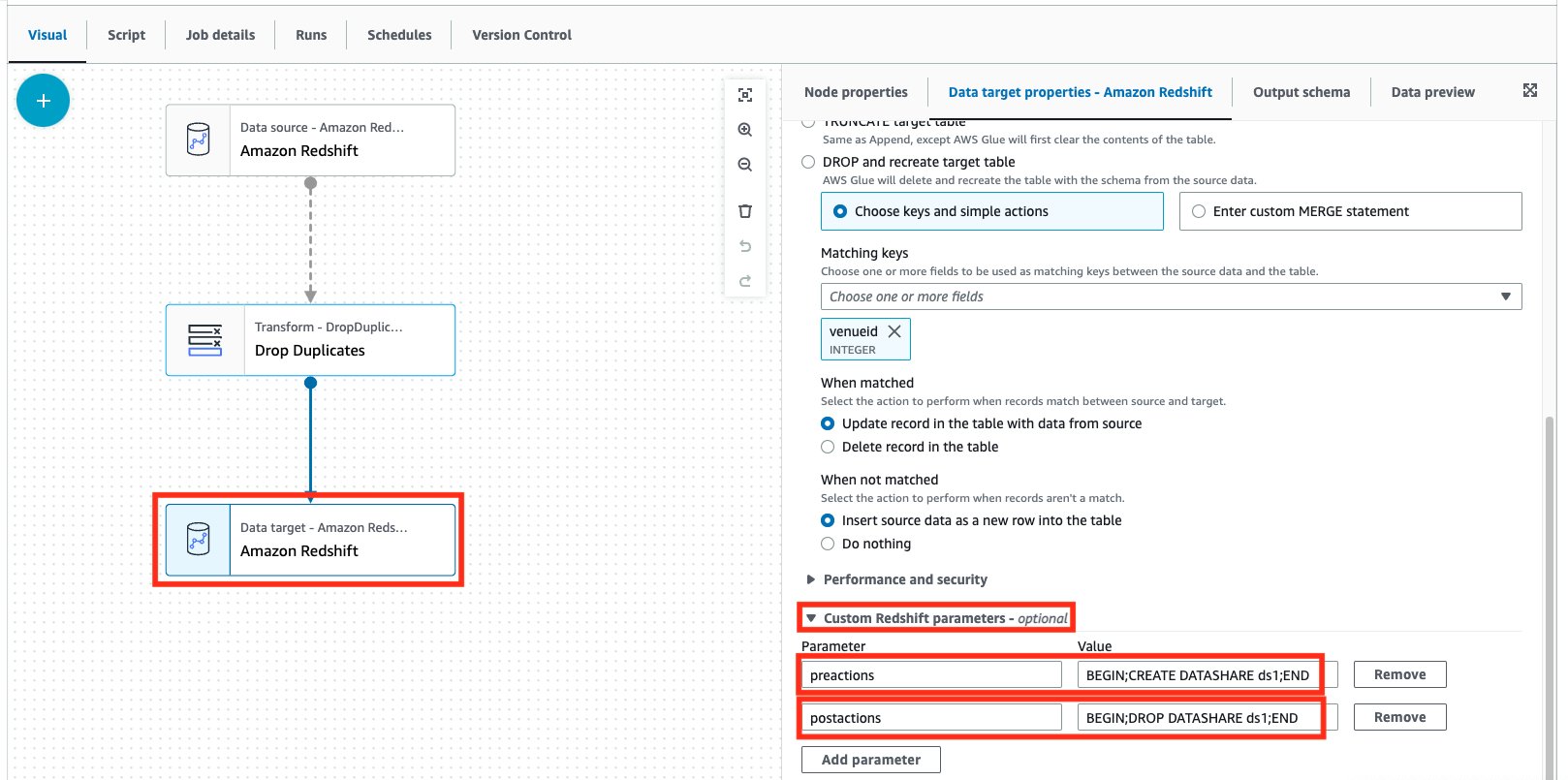
As you can see, we can define numerous Amazon Redshift declarations as a part of both the preactions and postactions specifications. Bear in mind that these declarations will bypass any existing preactions or postactions with your defined actions (as you can see in the following produced code).
Clean-up
To prevent extra expenses, ensure to erase any unneeded resources and files:
- Empty and erase the contents from the S3 short-term container
- If you released the sample CloudFormation stack, erase the CloudFormation stack by means of the AWS CloudFormation console. Ensure to empty the S3 container prior to you erase the container.
Conclusion
In this post, we discussed the brand-new AWS Glue Studio visual alternatives for carrying out checks out and composes from Amazon Redshift. We likewise saw the simpleness with which you can search your Amazon Redshift tables right from the AWS Glue Studio visual editor UI, and how to run your own custom-made SQL declarations versus your Amazon Redshift sources. We then checked out how to carry out basic ETL filling jobs versus Amazon Redshift with simply a couple of clicks, and showcased the brand-new Amazon Redshift MERGE declaration.
To dive deeper into the brand-new Amazon Redshift combinations for the AWS Glue Studio visual editor, take a look at Linking to Redshift in AWS Glue Studio
About the Authors
 Aniket Jiddigoudar is a Big Data Designer on the AWS Glue group. He deals with clients to assist enhance their huge information work. In his extra time, he takes pleasure in experimenting with brand-new food, playing computer game, and kickboxing.
Aniket Jiddigoudar is a Big Data Designer on the AWS Glue group. He deals with clients to assist enhance their huge information work. In his extra time, he takes pleasure in experimenting with brand-new food, playing computer game, and kickboxing.
 Sean Ma is a Principal Item Supervisor on the AWS Glue group. He has an 18+ year performance history of innovating and providing business items that open the power of information for users. Beyond work, Sean takes pleasure in diving and college football.
Sean Ma is a Principal Item Supervisor on the AWS Glue group. He has an 18+ year performance history of innovating and providing business items that open the power of information for users. Beyond work, Sean takes pleasure in diving and college football.