This is a visitor post co-written with Parag Doshi, Master Havanur, and Simon Guindon from Tricentis.
Tricentis is an international leader in constant screening for DevOps, cloud, and business applications. It has actually been well released given that the State of DevOps 2019 DORA Metrics were released that with DevOps, business can release software application 208 times more frequently and 106 times much faster, recuperate from occurrences 2,604 times much faster, and release 7 times less flaws. Speed modifications whatever, and constant screening throughout the whole CI/CD lifecycle is the secret. Nevertheless, speed is just understood when you have the self-confidence to launch software application as needed. Tricentis imparts that self-confidence by offering software application tools that allow Agile Constant Evaluating (ACT) at scale. Whether exploratory or automated, practical or efficiency, API or UI, targeting mainframes, custom-made applications, packaged applications, or cloud-native applications, Tricentis supplies an extensive suite of specialized constant screening tools that assist its consumers attain the self-confidence to launch as needed.
The next stage of Tricentis’ journey is to open insights throughout all screening tools. Groups might have a hard time to have a unified view of software application quality due to siloed screening throughout numerous diverse tools. For users that need a unified view of software application quality, this is inappropriate. In this post, we share how the AWS Data Laboratory assisted Tricentis to enhance their software application as a service (SaaS) with insights powered by Amazon Redshift
The difficulty
Tricentis supplies SaaS and on-premises options to countless consumers internationally. Every modification to software application worth screening is tracked in test management tools such as Tricentis qTest, test automation tools such as Tricentis Tosca or Tricentis Testim, or efficiency screening tools such as Tricentis NeoLoad. Although Tricentis has actually accumulated such information over a years, it stays untapped for important insights. Each of these tools has its own reporting abilities which can make it challenging to integrate the information for incorporated and actionable service insights.
In addition, the scale is considerable since the multi-tenant information sources offer a constant stream of screening activity, and our users need fast information revitalizes along with historic context for as much as a years due to compliance and regulative needs.
Lastly, information stability is of vital value. Every occasion in the information source can be appropriate, and our consumers do not endure information loss, bad information quality, or disparities in between the source and analytics originating from Tricentis. While aggregating, summing up, and lining up to a typical info design, all improvements need to not impact the stability of information from its source.
The service
Tricentis intends to deal with the difficulties of offering high volume, near-real-time, and aesthetically attractive reporting and analytics throughout the whole Tricentis item portfolio.
The preliminary client goals were:
- Offer export of information firmly available from the AWS Cloud
- Offer a preliminary set of pre-built control panels that offer instant service insights
- Beta test an option with early adopter consumers within 6 weeks
Thinking about the multi-tenant information source, Tricentis and the AWS Data Laboratory group crafted for the following restraints:
- Provide the end-to-end pipeline to load just the qualified consumers into an analytics repository
- Change the multi-tenant information into single-tenant information separated for each client in strictly segregated environments
Understanding that information will be merged throughout numerous sources released in any environment, the architecture required an enterprise-grade analytics platform. The information pipeline includes numerous layers:
- Consuming information from the source either as application occasions or alter information capture (CDC) streams
- Queuing information so that we can rewind and replay the information back in time without returning to the source
- Light improvements such as splitting multi-tenant information into single renter information to separate client information
- Continuing and providing information in a scalable and trusted lake home (information lake and information storage facility) repository
Some consumers will access the repository straight by means of an API with the correct guardrails for stability to integrate their test information with other information sources in their business, while other consumers will utilize control panels to get insights on screening. At first, Tricentis specifies these control panels and charts to allow insight on trial run, test traceability with requirements, and numerous other pre-defined usage cases that can be important to consumers. In the future, more abilities will be supplied to end-users to come up with their own analytics and insights.
How Tricentis and the AWS Data Laboratory had the ability to develop service insights in 6 weeks
Offered the difficulty of Tricentis Analytics with live consumers in 6 weeks, Tricentis partnered with the AWS Data Laboratory. From comprehensive style to a beta release, Tricentis had consumers anticipating to take in information from an information lake particular to just their information, and all of the information that had actually been created for over a years. Clients likewise needed their own repository, an Apache Parquet information lake, which would integrate with other information in the client environment to collect even higher insights.
The AWS account group proposed the AWS Data Laboratory Build Laboratory session to assist Tricentis speed up the procedure of developing and constructing their model. The Build Laboratory is a two-to-five-day extensive construct by a group of client home builders with assistance from an AWS Data Laboratory Solutions Designer. Throughout the Build Laboratory, the client will build a model in their environment, utilizing their information, with assistance on real-world architectural patterns and anti-patterns, along with methods for constructing efficient options, from AWS service professionals. Consisting of the pre-lab preparation work, the overall engagement period is three-six weeks and in the Tricentis case was 3 weeks: 2 for the pre-lab preparation work and one for the laboratory. The weeks that followed the laboratory consisted of go-to-market activities with particular consumers, paperwork, solidifying, security evaluations, efficiency screening, information stability screening, and automation activities.
The 2 weeks prior to the laboratory were utilized for the following:
- Comprehending the usage case and working backwards with an architecture
- Preparing the Tricentis group for the laboratory by providing all the training on the services to be utilized throughout the laboratory
For this service, Tricentis and AWS developed an information pipeline that takes in information from streaming, which remained in location prior to the laboratory, and this streaming has the database deals caught through CDC. In the streaming, the information from each table is separated by subject, and information from all the consumers begins the exact same subject (no seclusion). Since of that, a pipeline was developed to separate consumers to develop their tables separated by the schema on the last location at Amazon Redshift. The following diagram shows the service architecture.
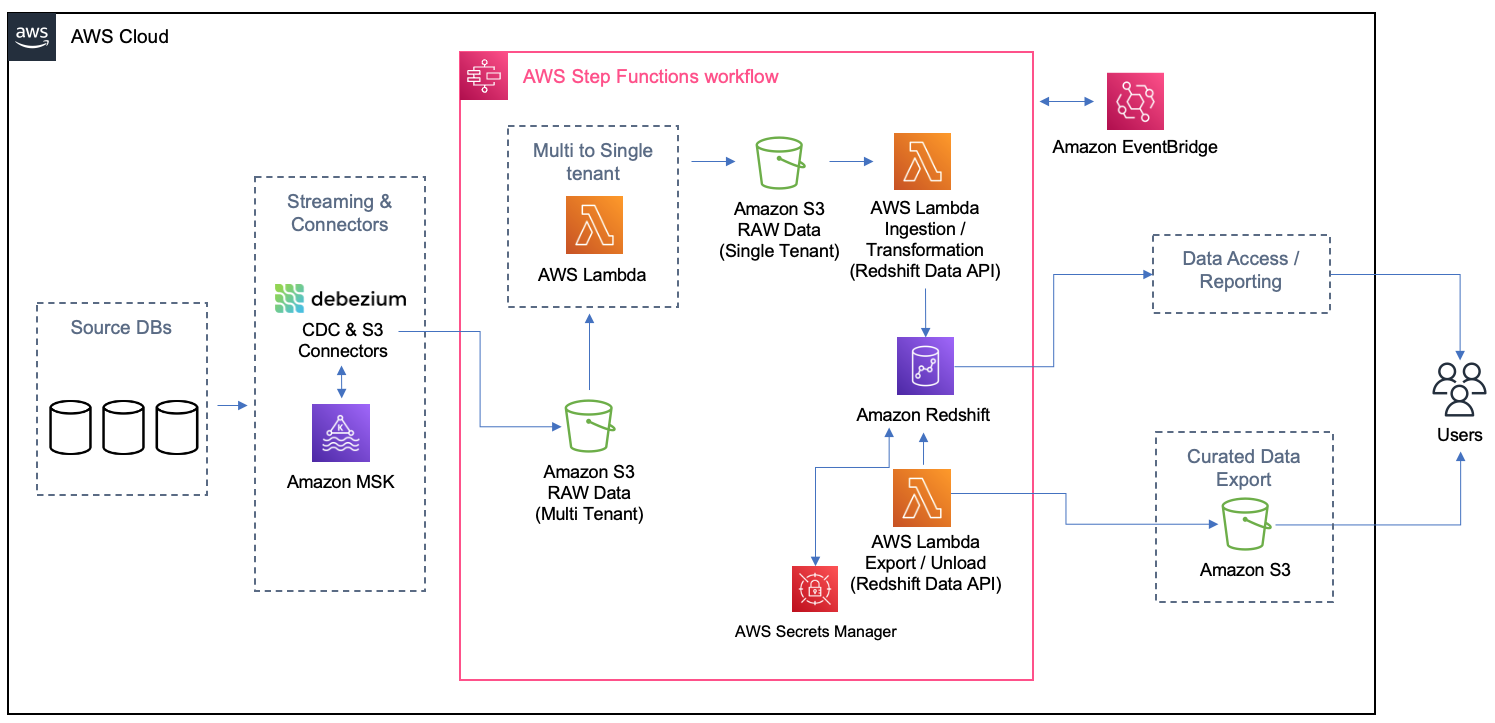
The main point of this architecture is to be event-driven with ultimate consistency. At any time brand-new test cases or test outcomes are developed or customized, occasions set off such that processing is instant and brand-new picture files are offered by means of an API or information is plucked the refresh frequency of the reporting or service intelligence (BI) tool. Each time the Amazon Simple Storage Service (Amazon S3) sink port from Apache Kafka provides a file on Amazon S3, Amazon EventBridge activates an AWS Lambda function to change the multi-tenant file into apart files, one per client per table, and land it on particular folders on Amazon S3. As the files are developed, another procedure is set off to fill the information from each client on their schema or table on Amazon Redshift. On Amazon Redshift, emerged views were utilized to get the questions for the control panels prepared and simpler to be gone back to the Apache Superset. Likewise, the emerged views were set up to revitalize instantly (with the autorefresh choice), so Amazon Redshift updates the information instantly in the emerged consider as quickly as possible after base tables modifications.
In the following areas, we information particular application difficulties and extra functions needed by consumers found along the method.
Information export
As mentioned previously, some consumers wish to get an export of their test information and develop their information lake. For these consumers, Tricentis supplies incremental information as Apache Parquet files and will have the capability to filter on particular tasks and particular date varieties. To make sure information stability, Tricentis utilizes its innovation referred to as Tricentis Data Stability (not part of the AWS Data Laboratory session).
Information security
The service utilizes the following information security guardrails:
- Information seclusion guardrails— Tricentis source databases systems are utilized by all consumers, and for that reason, information from various consumers remains in the exact same database. To separate customer-specific information, Tricentis has a special identifier that discriminates customer-specific information. All the questions filter information based upon the discriminator to get customer-specific information. EventBridge activates a Lambda function to change multi-tenant files to single-tenant (client) submits to land in customer-specific S3 folders. Another Lambda function is set off to fill information from customer-specific folders to their particular schema in Amazon Redshift. The latter Lambda function is information seclusion mindful and activates an alert and stops processing even more for any information that does not come from a particular client.
- Information gain access to guardrails— To make sure gain access to control, Tricentis used role-based gain access to control concepts to users and service represent particular job-related resources. Access to Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon S3, Amazon Relational Database Service (Amazon RDS), and Amazon Redshift was managed by giving advantages at the function level and designating those functions proper resources.
Pay per usage and direct expense scalability
Tricentis’ goal is to spend for the calculate and storage utilized and grow analytics facilities with direct expense scalability. To much better handle storage expenses in the information aircraft, Tricentis shops all raw and intermediate information in Amazon S3 storage in a compressed format. The Amazon MSK and Amazon Redshift is right-sized for the Tricentis analytics load and is permitted to scale up or down with no downtime based upon future service requirements. Information on all the shops, consisting of Amazon MSK, Amazon Redshift, and Amazon S3, undergoes tiered storage and retention policies per the client information retention and archival requirements to minimize the expense even more and offer direct expense scalability.
In the control aircraft, Debezium and Kafka Link resources are switched on and off, so you just spend for what you utilize. Lambda triggers are set off on an occasion or a schedule and switched off after finishing jobs.
Automated information stability
High information stability is an essential style concept behind analytics for the Tricentis platform. Luckily, Tricentis has actually an item called Tricentis Data Stability, which is utilized to automate the measurement of information stability throughout various information sources. The main point is to utilize the machine-generated information type and log series number (LSN) to show the current picture information from the modification information capture (CDC) streams. Tricentis reached the information stability automation turning point beyond the AWS Data Laboratory window by instantly activating Tosca DI at different phases of the AWS serverless architecture (detailed earlier), and since of that Tricentis had the ability to make sure anticipated record counts at every action, avoiding information loss or unintentional information adjustment. In future variations, Tricentis will have much deeper information stability confirmation record counts and include particular fields to make sure information quality (for instance, nullness) and semantic or format recognition. To date, the mix of CDC and information cleaning has actually led to ultra-high information stability when comparing source information to the last Parquet file contents.
Efficiency and information loss avoidance
Efficiency was tuned for optimum throughput at 3 phases in the pipeline:
- Information intake— Information stability throughout intake was considerably enhanced utilizing CDC occasions and permitted us to depend on the well-respected duplication systems in PostgreSQL and Kafka, which streamlined the system and removed a great deal of the previous information corrections that remained in location. The Amazon S3 sink port even more streams information into Amazon S3 in genuine time by separating information into fixed-sized files. Fixed-size information files prevent more latency due to unbound file sizes. As an outcome, information was greater quality and was streamed in genuine time at a much faster rate.
- Information change— Batch processing is extremely cost effective and calculate effective, and can reduce different possible efficiency concerns if properly executed. Tricentis utilizes batch change to move information from multi-tenant Amazon S3 to single-tenant Amazon S3 and in between single-tenant Amazon S3 to Amazon Redshift by micro-batch loading. The batch processing is staged to work within the Lamba invocations limitations and optimum Amazon Redshift connections limitations to keep the expense minimum. Nevertheless, the change pipeline is configurable to go actual time by processing every inbound S3 file on an EventBridge occasion.
- Information questions— Emerged views with proper sort secrets considerably enhance the efficiency of duplicated and foreseeable control panel work. Tricentis pipelines utilize vibrant information packing in views and precomputed lead to emerged views to flawlessly enhance the efficiency of control panels, in addition to establishing proper basic and compound sort secrets to speed up efficiency. Tricentis inquiry efficiency is more sped up by range-restricted predicates in sort secrets.
Execution difficulties
Tricentis worked within the default limitation of 1,000 concurrent Lambda function runs by tracking offered functions at any provided time and shooting just those numerous functions for which slots are offered. For the 10 GB memory limitation per function, Tricentis right-sized the Amazon S3 sink port created files and single-tenant S3 files to not go beyond 4 GB in size. The Lambda function throttling can be avoided by asking for a greater limitation of concurrent runs if that ends up being essential later on.
Tricentis likewise experienced some Amazon Redshift connection restrictions. Amazon Redshift has quotas and adjustable quotas that restrict making use of server resources. To successfully handle Amazon Redshift limitations of optimum connections, Tricentis utilized connection swimming pools to make sure ideal intake and stability.
Outcomes and next actions
The collective technique in between Tricentis and the AWS Data Laboratory permitted significant velocity and the capability to fulfill timelines for developing a huge information service that will benefit Tricentis consumers for several years. Because this writing, client onboarding, observability and signaling, and security scanning were automated as part of a DevSecOps pipeline.
Within 6 weeks, the group had the ability to beta an information export service for among Tricentis’ consumers.
In the future, Tricentis prepares for including numerous information sources, combine towards a typical, common language for screening information, and provide richer insights so that our consumers can have the right information in a single view and boost self-confidence in their shipment of software application at scale and speed.
Conclusion
In this post, we strolled you through the journey the Tricentis group took with the AWS Data Laboratory throughout their involvement in a Build Laboratory session. Throughout the session, the Tricentis group and AWS Data Laboratory collaborated to determine a best-fit architecture for their usage cases and execute a model for providing brand-new insights for their consumers.
To find out more about how the AWS Data Laboratory can assist you turn your concepts into options, check out AWS Data Laboratory
About the Authors
 Parag Doshi is Vice President of Engineering at Tricentis, where he continues to lead towards the vision of Development at the Speed of Creativity. He brings development to market by constructing first-rate quality engineering SaaS such as qTest, the flagship test management item, and its hidden analytics abilities, which opens software application advancement lifecycle insights throughout all kinds of screening. Prior to Tricentis, Parag was the creator of Anthem’s Cloud Platform Providers, where he drove a hybrid cloud and DevSecOps ability and moved 100 mission-critical applications. He allowed Anthem to construct a brand-new drug store advantages management service in AWS, leading to $800 million in overall operating gain for Anthem in 2020 per Forbes and CNBC. He likewise held posts at Hewlett-Packard, having numerous functions consisting of Chief Technologist and head of architecture for DXC’s Virtual Private Cloud, and CTO for HP’s Application Providers in the Americas area.
Parag Doshi is Vice President of Engineering at Tricentis, where he continues to lead towards the vision of Development at the Speed of Creativity. He brings development to market by constructing first-rate quality engineering SaaS such as qTest, the flagship test management item, and its hidden analytics abilities, which opens software application advancement lifecycle insights throughout all kinds of screening. Prior to Tricentis, Parag was the creator of Anthem’s Cloud Platform Providers, where he drove a hybrid cloud and DevSecOps ability and moved 100 mission-critical applications. He allowed Anthem to construct a brand-new drug store advantages management service in AWS, leading to $800 million in overall operating gain for Anthem in 2020 per Forbes and CNBC. He likewise held posts at Hewlett-Packard, having numerous functions consisting of Chief Technologist and head of architecture for DXC’s Virtual Private Cloud, and CTO for HP’s Application Providers in the Americas area.
 Master Havanur works as a Principal, Big Data Engineering and Analytics group in Tricentis. Master is accountable for information, analytics, advancement, combination with other items, security, and compliance activities. He makes every effort to deal with other Tricentis items and consumers to enhance information sharing, information quality, information stability, and information compliance through the modern-day huge information platform. With over twenty years of experience in information warehousing, a range of databases, combination, architecture, and management, he flourishes for quality.
Master Havanur works as a Principal, Big Data Engineering and Analytics group in Tricentis. Master is accountable for information, analytics, advancement, combination with other items, security, and compliance activities. He makes every effort to deal with other Tricentis items and consumers to enhance information sharing, information quality, information stability, and information compliance through the modern-day huge information platform. With over twenty years of experience in information warehousing, a range of databases, combination, architecture, and management, he flourishes for quality.
 Simon Guindon is a Designer at Tricentis. He has competence in massive dispersed systems and database consistency designs, and deals with groups in Tricentis around the globe on scalability and high schedule. You can follow his Twitter @simongui.
Simon Guindon is a Designer at Tricentis. He has competence in massive dispersed systems and database consistency designs, and deals with groups in Tricentis around the globe on scalability and high schedule. You can follow his Twitter @simongui.
 Ricardo Serafim is a Senior AWS Data Laboratory Solutions Designer. With a concentrate on information pipelines, information lakes, and information storage facilities, Ricardo assists consumers develop an end-to-end architecture and test an MVP as part of their course to production. Beyond work, Ricardo enjoys to take a trip with his household and watch soccer video games, generally from the “Timão” Sport Club Corinthians Paulista.
Ricardo Serafim is a Senior AWS Data Laboratory Solutions Designer. With a concentrate on information pipelines, information lakes, and information storage facilities, Ricardo assists consumers develop an end-to-end architecture and test an MVP as part of their course to production. Beyond work, Ricardo enjoys to take a trip with his household and watch soccer video games, generally from the “Timão” Sport Club Corinthians Paulista.