The error and extreme optimism of expense quotes are typically pointed out as dominant consider DoD expense overruns. Causal knowing can be utilized to recognize particular causal elements that are most accountable for intensifying expenses. To consist of expenses, it is necessary to comprehend the elements that drive expenses and which ones can be managed. Although we might comprehend the relationships in between specific elements, we do not yet different the causal impacts from non-causal analytical connections.
Causal designs ought to transcend to conventional analytical designs for expense evaluation: By determining real causal elements rather than analytical connections, expense designs ought to be more suitable in brand-new contexts where the connections may no longer hold. More significantly, proactive control of task and job results can be accomplished by straight stepping in on the reasons for these results. Till the advancement of computationally effective causal-discovery algorithms, we did not have a method to get or confirm causal designs from mainly observational information– randomized control trials in systems and software application engineering research study are so not practical that they are almost difficult.
In this post, I explain the SEI Software Application Expense Forecast and Control (shortened as SCOPE) task, where we use causal-modeling algorithms and tools to a big volume of task information to recognize, determine, and test causality. The post constructs on research study carried out with Expense Nichols and Anandi Hira at the SEI, and my previous coworkers David Zubrow, Robert Stoddard, and Sarah Sheard We looked for to recognize some reasons for task results, such as expense and schedule overruns, so that the expense of obtaining and running software-reliant systems and their growing ability is foreseeable and manageable.
We are establishing causal designs, consisting of structural formula designs (SEMs), that supply a basis for
- determining the effort, schedule, and quality outcomes of software application tasks under various circumstances (e.g., Waterfall versus Agile)
- approximating the outcomes of interventions used to a task in action to a modification in requirements (e.g., a modification in objective) or to assist bring the task back on track towards accomplishing expense, schedule, and technical requirements.
An instant advantage of our work is the recognition of causal elements that supply a basis for managing program expenses. A longer term advantage is the capability to utilize causal designs to work out software application agreements, style policy, and rewards, and notify might-/ should-cost and cost efforts.
Why Causal Knowing?
To methodically minimize expenses, we usually need to recognize and think about the several reasons for a result and thoroughly relate them to each other. A strong connection in between an aspect X and expense might stem mostly from a typical reason for both X and expense. If we stop working to observe and change for that typical cause, we might improperly associate X as a substantial reason for expense and use up energy (and expenses), fruitlessly stepping in on X anticipating expense to enhance.
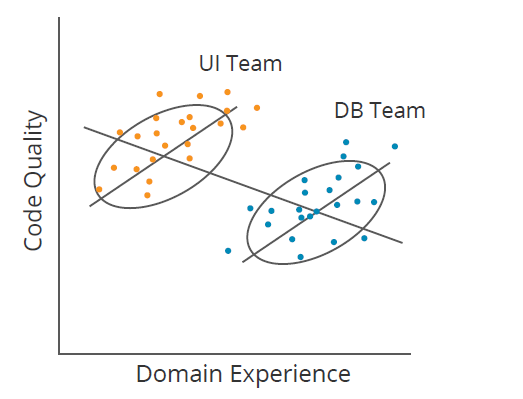
Another obstacle to connections is shown by Simpson’s Paradox For instance, in Figure 1 listed below, if a program supervisor did not section information by group (Interface [UI] and Database [DB]), they may conclude that increasing domain experience lowers code quality (down line); nevertheless, within each group, the reverse holds true (2 upward lines). Causal knowing determines when elements like group subscription rationalize (or moderate) connections. It works for far more complex datasets too.
{kind=link}
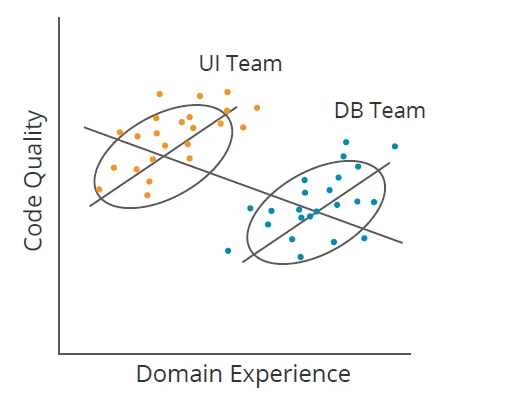
Figure 1: Illustration of Simpson’s Paradox.
Causal knowing is a type of artificial intelligence that concentrates on causal reasoning. Artificial intelligence produces a design that can be utilized for forecast from a dataset. Causal knowing varies from artificial intelligence in its concentrate on modeling the data-generation procedure. It addresses concerns such as
- How did the information happen the method it is?
- What information is driving which results?
Of specific interest in causal knowing is the difference in between conditional reliance and conditional self-reliance For instance, if I understand what the temperature level is outdoors, I can discover that the variety of shark attacks and ice cream sales are independent of each other (conditional self-reliance). If I understand that an automobile will not begin, I can discover that the condition of the gas tank and battery depend on each other (conditional reliance) due to the fact that if I understand among these is great, the other is not most likely to be great.
Systems and software application engineering scientists and professionals who look for to enhance practice typically uphold theories about how finest to carry out system and software application advancement and sustainment. Causal knowing can assist check the credibility of such theories. Our work looks for to evaluate the empirical structure for heuristics and general rules utilized in handling programs, preparing programs, and approximating expenses.
Much previous work has actually concentrated on utilizing regression analysis and other methods. Nevertheless, regression does not compare causality and connection, so acting upon the outcomes of a regression analysis might stop working to affect results in the preferred method. By obtaining functional understanding from observational information, we produce actionable details and use it to supply a greater level of self-confidence that interventions or restorative actions will attain preferred results.
The copying from our research study emphasize the value and obstacle of determining real causal elements to describe phenomena.
Contrary and Unexpected Outcomes
{kind=link}
{kind=link}

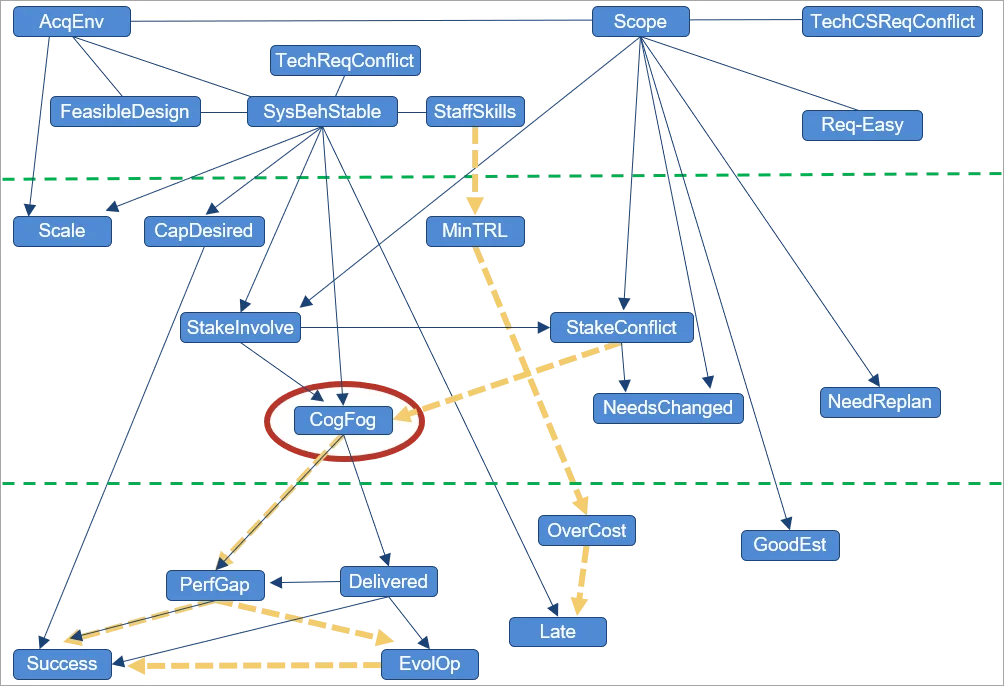
Figure 2: Intricacy and Program Success.
Figure 2 reveals a dataset established by Sarah Sheard that consisted of around 40 procedures of intricacy (elements), looking for to recognize what kinds of intricacy drive success versus failure in DoD programs (just those elements discovered to be causally ancestral to program success are revealed). Although several kinds of intricacy impact program success, the only constant motorist of success or failure that we consistently discovered is cognitive fog, which includes the loss of intellectual functions, such as believing, keeping in mind, and thinking, with adequate seriousness to hinder everyday performance.
Cognitive fog is a state that groups often experience when needing to constantly handle conflicting information or made complex circumstances. Stakeholder relationships, the nature of stakeholder participation, and stakeholder dispute all impact cognitive fog: The relationship is among direct causality (relative to the elements consisted of in the dataset), represented in Figure 2 by edges with arrowheads. This relationship indicates that if all other elements are repaired– and we alter just the quantity of stakeholder participation or dispute– the quantity of cognitive fog modifications (and not the other method around).
Sheard’s work determined what kinds of program intricacy drive or hinder program success. The 8 consider the leading horizontal section of Figure 2 are elements offered at the start of the program. The bottom 7 are elements of program success. The middle 8 are elements offered throughout program execution. Sheard discovered 3 consider the upper or middle bands that had pledge for intervention to enhance program success. We used causal discovery to the very same dataset and found that a person of Sheard’s elements, variety of tough requirements, appeared to have no causal impact on program success (and therefore does not appear in the figure). Cognitive fog, nevertheless, is a controling aspect. While stakeholder relationships likewise contribute, all those arrows go through cognitive fog. Plainly, the suggestion for a program supervisor based upon this dataset is that sustaining healthy stakeholder relationships can make sure that programs do not come down into a state of cognitive fog.
Direct Reasons For Software Application Expense and Arrange
Readers acquainted with the Useful Expense Design (COCOMO) or Constructive Systems Engineering Expense Design (COSYSMO) might question what those designs would have appeared like had actually causal knowing been utilized in their advancement, while sticking to the very same familiar formula structure utilized by these designs. We just recently dealt with a few of the scientists accountable for developing and keeping these designs[formerly, members of the late Barry Boehm‘s group at the University of Southern California (USC)] We coached these scientists on how to use causal discovery to their exclusive datasets to get insights into what drives software application expenses.
From amongst the more than 40 elements that COCOMO and COSYSMO explain, these are the ones that we discovered to be direct motorists of expense and schedule:
COCOMO II effort motorists:
- size (software application lines of code, SLOC)
- group cohesion
- platform volatility
- dependability
- storage restrictions
- time restrictions
- item intricacy
- procedure maturity
- danger and architecture resolution
COCOMO II schedule motorists
- size (SLOC)
- platform experience
- schedule restraint
- effort
COSYSMO 3.0 effort motorists
- size
- level-of-service requirements
In an effort to recreate expense designs in the design of COCOMO and COSYSMO, however based upon causal relationships, we utilized a tool called Tetrad to obtain charts from the datasets and after that instantiate a couple of easy mini-cost-estimation designs. Tetrad is a suite of tools utilized by scientists to find, parameterize, quote, imagine, test, and anticipate from causal structure We carried out the following 6 actions to produce the mini-models, which produce possible expense quotes in our screening:
- Disallow expense motorists to have direct causal relationships with one another. (Such self-reliance of expense motorists is a main style concept for COCOMO and COSYSMO.)
- Rather of consisting of each scale aspect as a variable (as we carry out in effort
multipliers), change them with a brand-new variable: scale aspect times LogSize. - Apply causal discovery to the modified dataset to get a causal chart.
- Usage Tetrad design evaluation to get parent-child edge coefficients.
- Raise the formulas from the resulting chart to form the mini-model, reapplying evaluation to effectively figure out the obstruct.
- Examine the fit of the resulting design and its predictability.
{kind=link}
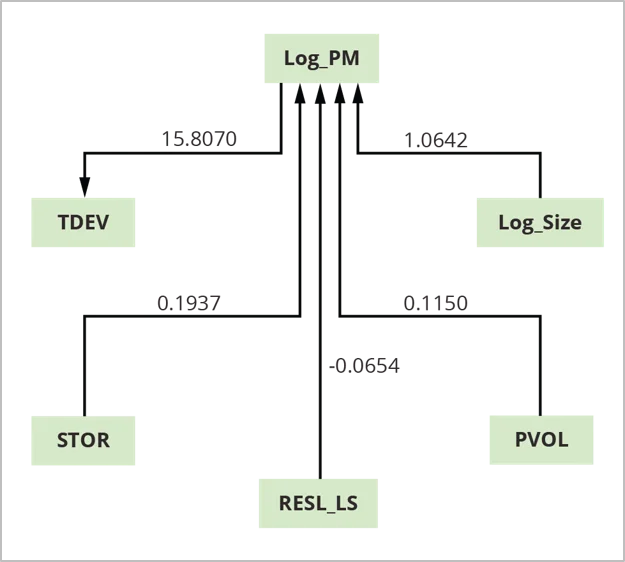
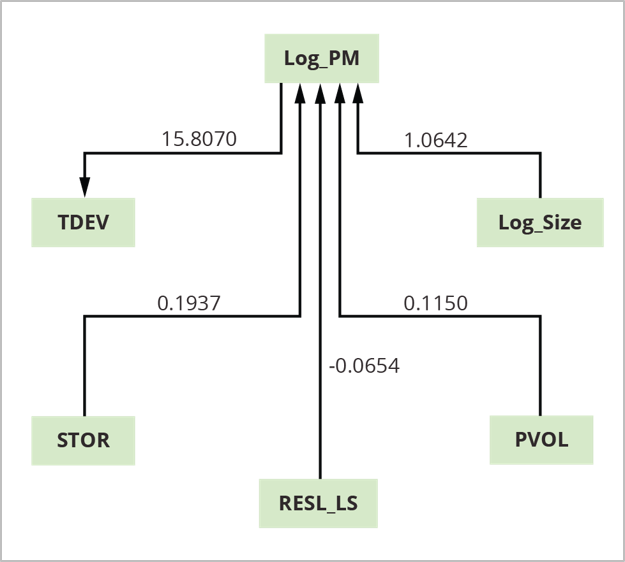
Figure 3: COCOMO II Mini-Cost Estimate Design.
The benefit of the mini-model is that it determines which elements, amongst lots of, are most likely to drive expense and schedule. According to this analysis utilizing COCOMO II calibration information, 4 elements– log size (Log_Size), platform volatility (PVOL), dangers from insufficient architecture times log size (RESL_LS), and memory storage (STOR)– are direct causes (motorists) of task effort (Log_PM). Log_PM is a chauffeur of the time to establish (TDEV).
We carried out a comparable analysis of systems-engineering effort that revealed a comparable relationship with schedules and time to establish. We determined 6 elements that have direct causal impact on effort. Outcomes showed that if we wished to alter effort, we would be much better off altering among these variables or among their direct causes. If we were to step in on any other variable, the impact on effort would likely be partly obstructed or might break down system ability or quality. The causal chart in Figure 4 assists to show the requirement to be cautious about stepping in on a task. These outcomes are likewise generalizable and assist to recognize the direct causal relationships that continue beyond the bounds of a specific dataset or population that we sample.
Agreement Chart for U.S. Army Software Application Sustainment
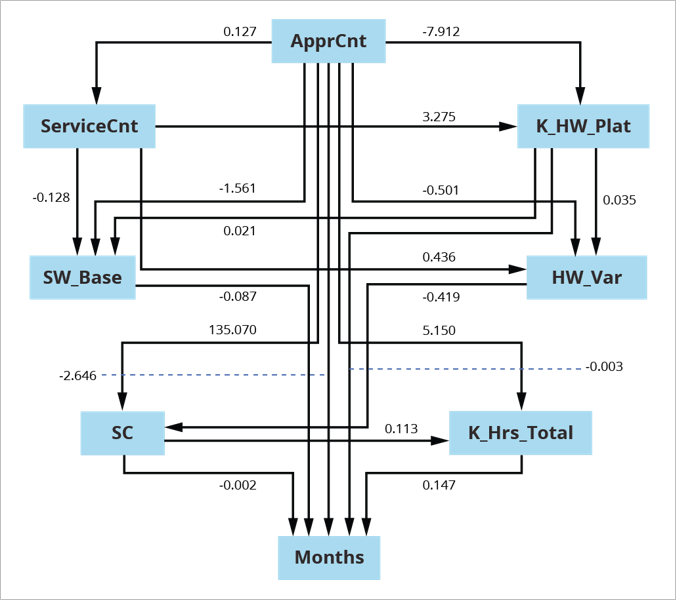{kind=link}
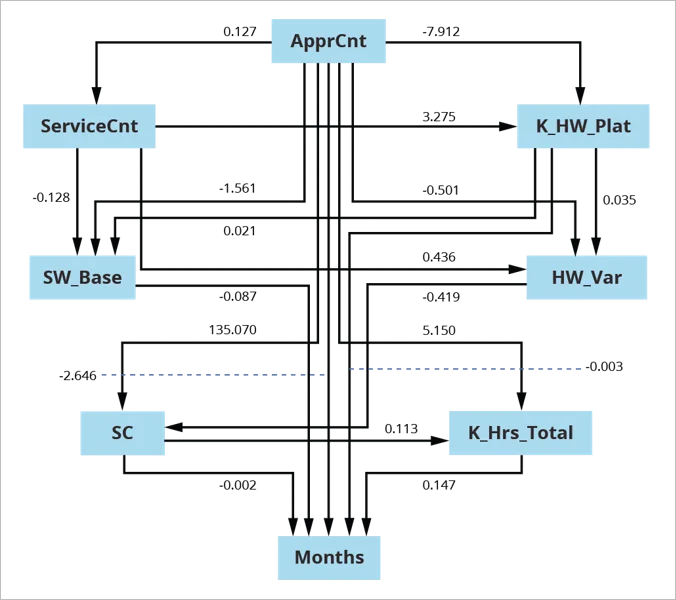
Figure 4: Agreement Chart for U.S. Army Software Application Sustainment.
In this example, we segmented a U.S. Army sustainment dataset into [superdomain, acquisition category (ACAT) level] sets, leading to 5 sets of information to browse and approximate. Segmenting in this method attended to high fan-out for typical causes, which can cause structures common of Simpson’s Paradox. Without segmenting by [superdomain, ACAT-level] sets, charts are various than when we section the information. We developed the agreement chart displayed in Figure 4 above from the resulting 5 browsed and fitted designs.
For agreement evaluation, we pooled the information from private searches with information that was formerly left out due to the fact that of missing out on worths. We utilized the resulting 337 releases to approximate the agreement chart utilizing Mplus with Bootstrap in evaluation.
This design is a direct out-of-the-box evaluation, accomplishing great design fit on the very first shot.
Our Option for Using Causal Knowing to Software Application Advancement
We are using causal knowing of the kind displayed in the examples above to our datasets and those of our partners to develop essential cause– impact relationships amongst task elements and results. We are using causal-discovery algorithms and information analysis to these cost-related datasets. Our method to causal reasoning is principled (i.e., no cherry selecting) and robust (to outliers). This method is remarkably helpful for little samples, when the variety of cases is less than 5 to 10 times the variety of variables.
If the datasets are exclusive, the SEI trains partners to carry out causal searches by themselves as we made with USC. The SEI then requires details just about what dataset and search specifications were utilized along with the resulting causal chart.
Our general technical method for that reason includes 4 threads:
- finding out about the algorithms and their various settings
- motivating the developers of these algorithms (Carnegie Mellon Department of Viewpoint) to develop brand-new algorithms for evaluating the loud and little datasets more common of software application engineering, specifically within the DoD
- continuing to deal with our partners at the University of Southern California to get additional insights into the driving elements that impact software application expenses
- providing preliminary outcomes and therefore getting expense datasets from expense estimators all over and from the DoD in specific
Speeding Up Development in Software Application Engineering with Causal Knowing
Understanding which elements drive particular program results is necessary to supply greater quality and protected software application in a prompt and budget-friendly way. Causal designs provide much better insight for program control than designs based upon connection. They prevent the threat of determining the incorrect things and acting upon the incorrect signals.
Development in software application engineering can be sped up by utilizing causal knowing; determining intentional strategies, such as programmatic choices and policy formula; and focusing measurement on elements determined as causally associated to results of interest.
In coming years, we will
- examine factors and measurements of quality
- measure the strength of causal relationships (called causal evaluation)
- look for duplication with other datasets and continue to fine-tune our approach
- incorporate the outcomes into a combined set of decision-making concepts
- utilize causal knowing and other analytical analyses to produce extra artifacts to make Measuring Unpredictability in Early Lifecycle Expense Estimate (QUELCE) workshops more efficient
We are persuaded that causal knowing will speed up and provide pledge in software application engineering research study throughout lots of subjects. By validating causality or unmasking standard knowledge based upon connection, we intend to notify when stakeholders ought to act. Our company believe that typically the incorrect things are being determined and actions are being handled incorrect signals (i.e., primarily on the basis of viewed or real connection).
There is substantial pledge in continuing to take a look at quality and security results. We likewise will include causal evaluation into our mix of analytical methods and utilize extra equipment to measure these causal reasonings. For this we require your assistance, access to information, and partners who will supply this information, discover this approach, and perform it by themselves information. If you wish to assist, please call us.